ANGRY TROJANS
Play Angry Birds using the power of AI
BACKGROUND AND OVERVIEW
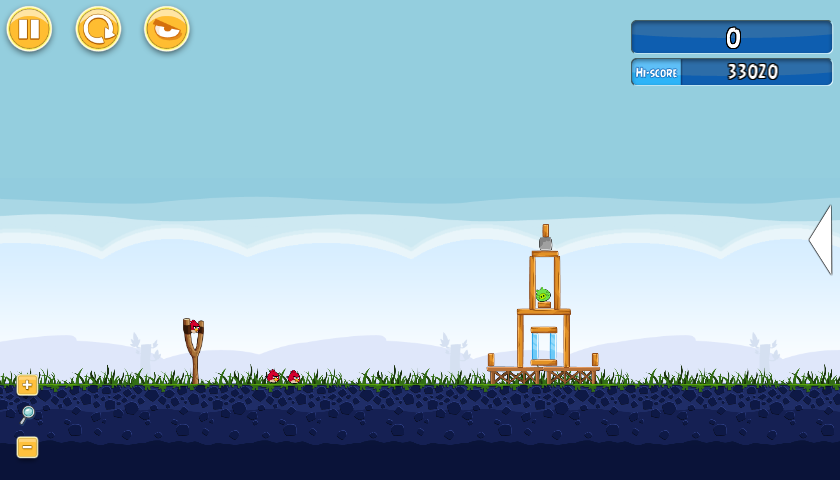
Angry Birds is a game where the player shoots birds using a slingshot into pigs' structures. The structures are built using various types of blocks. The objective of the player is to destroy all green pigs while using the least amount of birds. The birds gain different abilities as the level progresses.
The game is primarily developed for mobile platforms (IOS/Android). For our experiments, we are using an offline version that runs in a legacy version of chromium. We use the java websocket to connect to an chrome extension to control the player input.
The environment at any time would be a fully zoomed out screenshot. And for each action, we need 2 parameters to control the bird, the angle and the tap time(to simplify the problem, we only consider shooting the bird at 100% velocity). For the angle, 0 means pulling the bird to the right and increasing the angle will rotate the bird counterclockwise. The tap would be an integer in millisecond and the Action Robot will wait for that long to tap and use the bird’s ability. We could also zoom in and out, switch or restart levels, and do a screenshot at any time if we wish.
We aim to apply our agent to the first three major stages in the game, each containing 21 levels (63 levels in total). The primary goal of our agent is to maximus the combined average score. Certain levels will be skipped due to technical reasons. Right now, we are only considering the first 9 levels of the game which contains only the red birds(which have no ability). We will move on to more complex levels later. We have experimented with a simple rule based agent, BFS, CNN multi-label classification and reinforcement learning using a MDP structure. All of these approaches are explained in details below under methodology.
METHODOLOGY
SIMPLE RULE BASED AGENT
This is our first attempt at the problem. The agent uses a simple rule of “aiming at the pigs directly. When given a screenshot of the environment, the agent will pick a pig on screen and shoot a bird at a random pig's location while ignoring all other structures in the environment. Since pigs have a green color unique to them, finding their pixels in the screenshot is fairly easy. We also need to find the pixels that contain the slingshot and the bird on the left half of the screenshot. Once the x, y coordinates are obtained, we calculate the trajectory that the bird needs to travel and the launch angle associated with it using the following function derived from Newton’s Law.
The x and y here are a relative position of the pig to the bird, the position of the pig while having the bird centered at (0, 0). Gravity g is a constant of 1 unit. The velocity is calibrated to be the maximum velocity(we only consider shooting the bird at full swing). The result of this agent can be found below.
Breadth-First-Search
We want to try a classic search algorithm and see how it performs in Angry Bird. The branching factor is huge for this problem. We have angles from 0 degrees(pulling the bird to the left) to 90 degrees(pulling the bird down), we ignore angles that result in the bird hitting the ground too early or going backwards. On top of that, we have a taptime that goes from 0 to the time the bird hits anything measured in millisecond. However, the depth of the search is fairly shallow. We only have 4 to 6 birds for each level so the maximum depth of this search is 6. Also this game does take into consideration the time it takes to arrive at a solution which means a BFS for this problem is feasible.
We are also only considering shooting the birds at max speed. To reduce the search space, we ignore branches that are not meaningful to explore. Ex, we stop if a bird does not hit anything and produces a delta score of zero.
The time it takes to produce a solution varies between levels, but most of the time it will take 4+ hours. There are two reasons behind BFS taking this long to complete. Because we are using the game itself to evaluate each action, we need to wait for the animation of the game to complete before we can capture the delta score from the screenshot. Not only that, we need to start from the initial state each time we explore a new branch because we cannot save and reload an intermediate game state.
If we wish to continue with this approach, we have the following plans to tackle the above bottlenecks. We would build a physics engine in Unity to simulate the environment of Angry Birds. We will use a vision module to detect the objects in the screenshot and rebuild them in the physics engine and then perform the search. This would allow us to skip all animations and reload intermediate game states.
Knowledge-based Agent
Aim at Round Rock Strategy:
In this strategy, the agent will try to find a round rock in the scene that is located higher than some pigs and try to shoot a bird towards it.
Aim at TNT Strategy:
When there are TNTs in the scene, the agent will shoot a bird aiming at the TNTs and try to trigger an explosion.
Deep Reinforcement Learning Agents
We explored policy optimization and actor critic techniques in Angry Birds game. In specific, we implements Reinforce Agent, DDQN Agent, and TRPO Agent.
We trained our model on 1st to 18th level in stage 1 and some selected level in stage 2 and stage 3 for all our five DRL models. and then we tested our model on the last three level in stage 1.

Our New Settings
- Greedy Multi-Armed Bandit Problem
we are excited to presents our new settings of Angry Bird Games, as long as our implementation of our new settings comparing to traditional MDP set ups. It based on two nice properties for Angry Bird Games.
1. Neighbours of a good angel is also good
2.Neighbours of a good tap time is also good
Assumption 1
The maximum score you can get by distoying all structures using one bird is less than 10000 points
Assumption 2
Given the angle to shoot, the tap time can be dipicted as a Gaussian initialed at some given tap position
Assumption 3
Given tap time and shooting angles, the reward we get by shooting this angle and tap is always fixed

Under our new assumptions, we can reduce our action space from 90 * 25 to only 90 and we also use upper confidence bound instead of the traditional epsilon greedy methods.
Multi-label Classification Agents
Here we propose a framework using multi-label classification methods to break down the task of playing angry birds. By discretizing the shooting angles, the agents employs deep neural network to discriminate good and bad shots, with game data preprocessed.
The agent is based on greedy approach and learns context-free shooting techniques, where it solely focuses on the current shot and ignores the interrelationship of serial shots. Thus, the agent are more likely to "improvise" given any situation.

For the performance of the agent, on one hand, the framework provides computation efficient models which highly reduces the complexity of the task.
And on the other hand, it brings novlty beyong the human-understood planning.